
📝 Publications
*denotes co-first authors
🔊 Spatial Audio
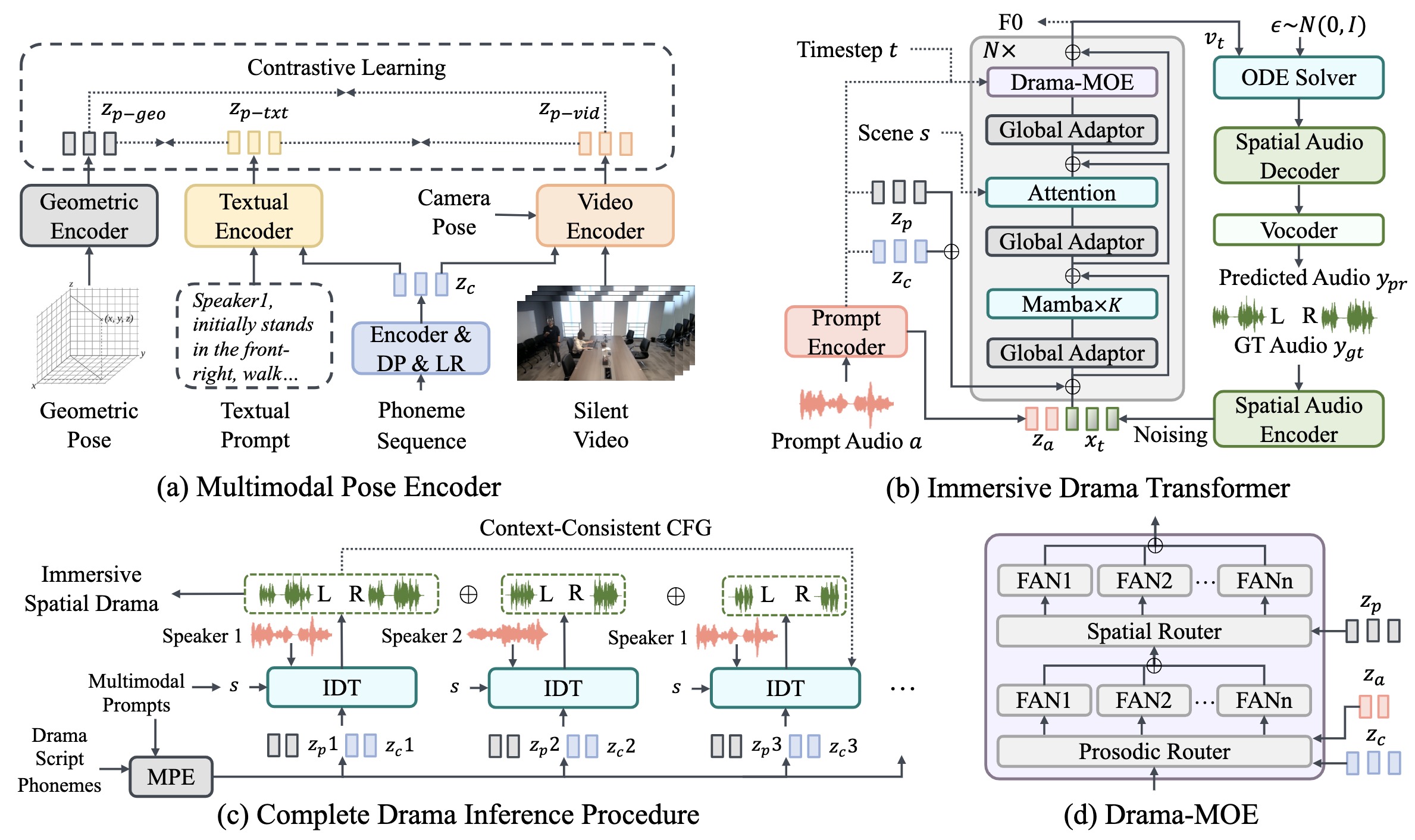
ISDrama: Immersive Spatial Drama Generation through Multimodal Prompting
Yu Zhang, Wenxiang Guo, Changhao Pan, et al.

- MRSDrama is the first multimodal recorded spatial drama dataset, containing binaural drama audios, scripts, videos, geometric poses, and textual prompts.
- ISDrama is the first immersive spatial drama generation model through multimodal prompting.
- Our work is promoted by multiple media and forums, such as
,
, and
.
IJCNLP-AACL 2025ASAudio: A Survey of Advanced Spatial Audio Research, Zhiyuan Zhu*, Yu Zhang*, Wenxiang Guo*, et al. |ACM-MM 2025A Multimodal Evaluation Framework for Spatial Audio Playback Systems: From Localization to Listener Preference, Changhao Pan*, Wenxiang Guo*, Yu Zhang*, et al. |NeurIPS 2025MRSAudio: A Large-Scale Multimodal Recorded Spatial Audio Dataset with Refined Annotations, Wenxiang Guo*, Changhao Pan*, Zhiyuan Zhu*, Xintong Hu*, Yu Zhang*, et al. |


🎼 Music
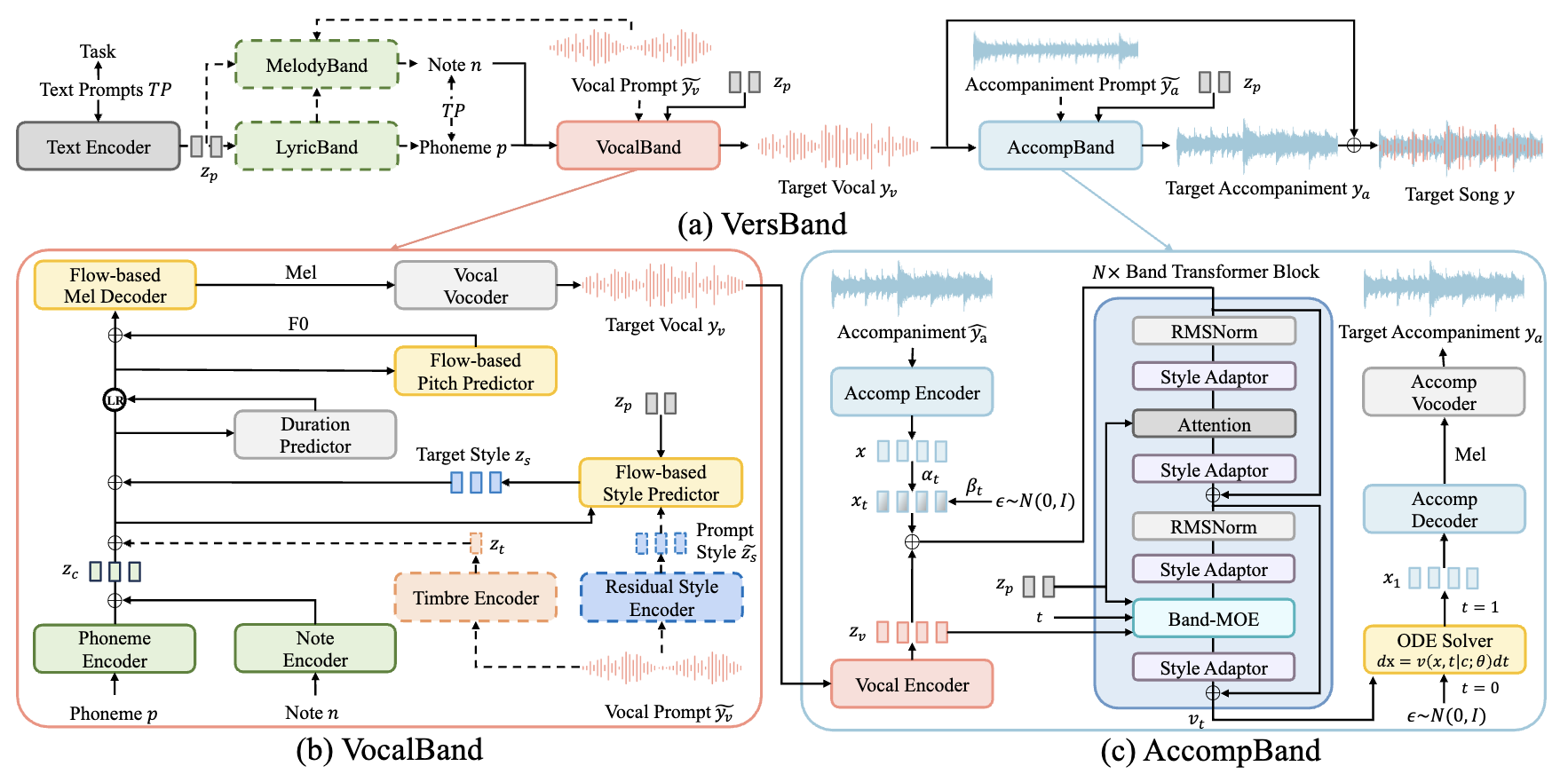
Versatile Framework for Song Generation with Prompt-based Control
Yu Zhang, Wenxiang Guo, Changhao Pan, et al.

- VersBand is a multi-task song generation framework for synthesizing high-quality, aligned songs with prompt-based control.
- Our work is promoted by multiple media and forums, such as
🎙️ Singing Voice
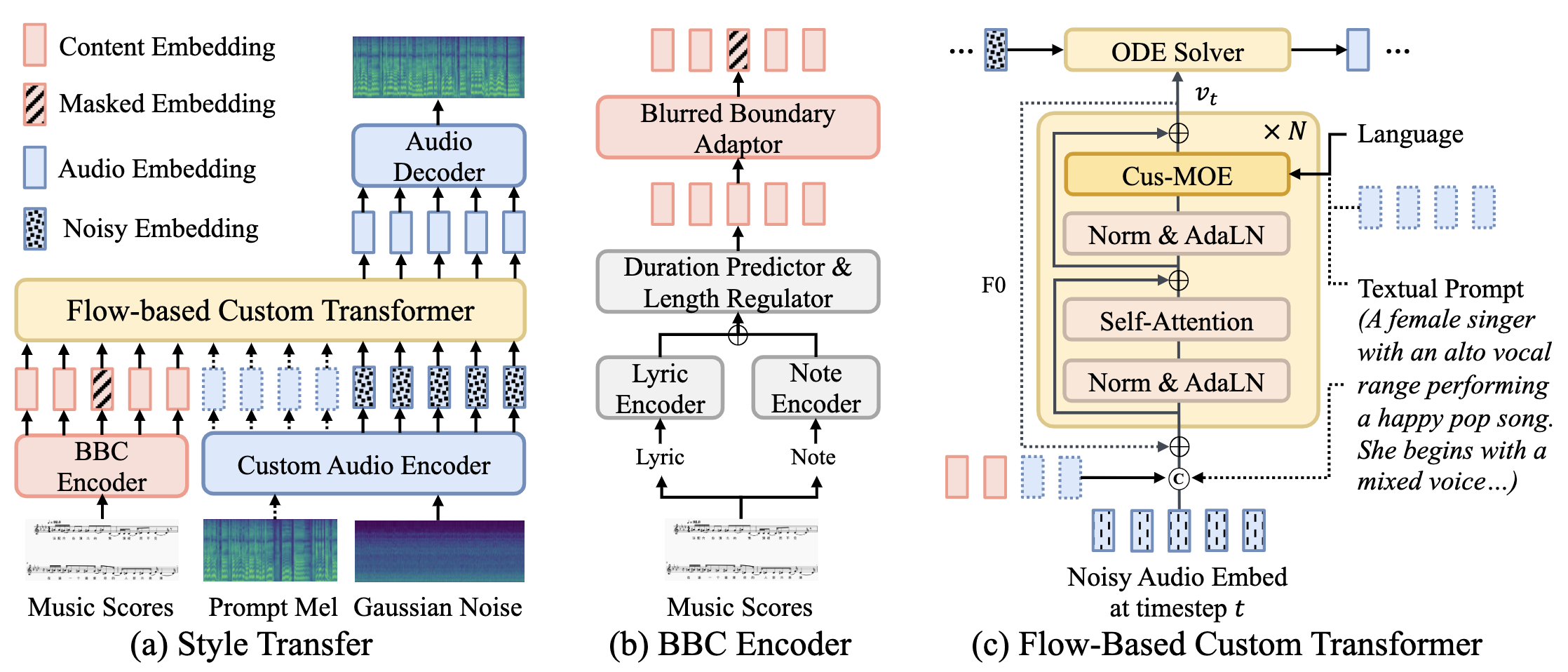
TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis
Yu Zhang, Ziyue Jiang, Ruiqi Li, et al.

- TCSinger 2 is a multi-task multilingual zero-shot SVS model with style transfer and style control based on various prompts.
- Our work is promoted by multiple media and forums, such as
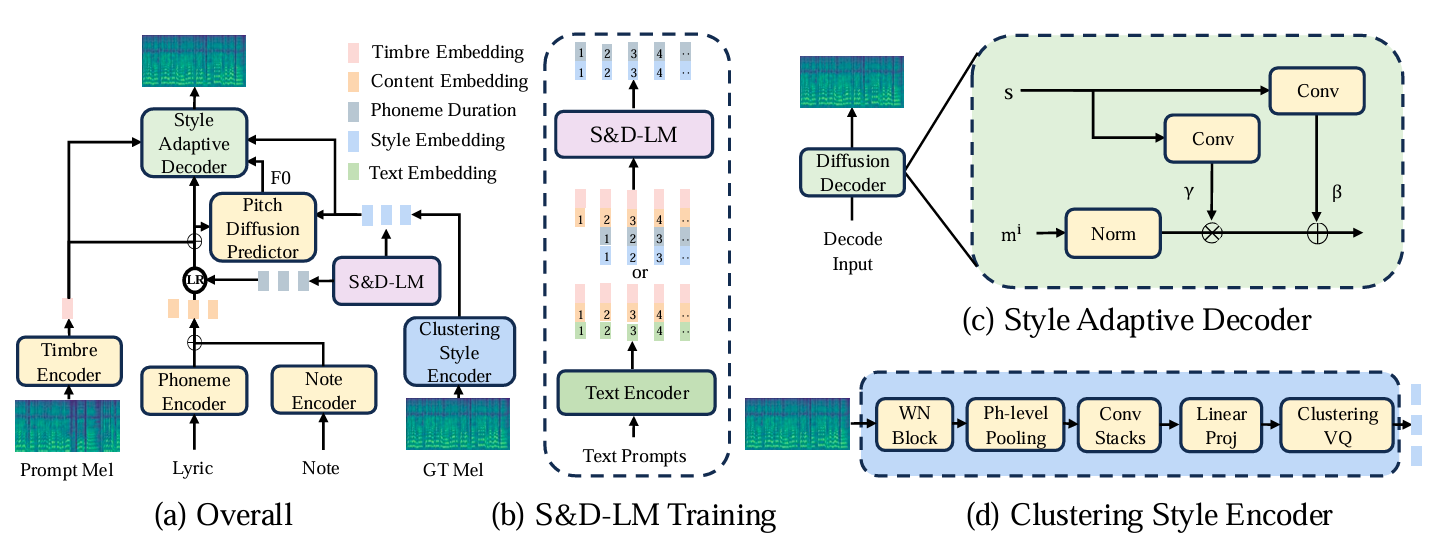
TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
Yu Zhang, Ziyue Jiang, Ruiqi Li, et al.

- TCSinger is the first zero-shot SVS model for style transfer across cross-lingual speech and singing styles, along with multi-level style control.
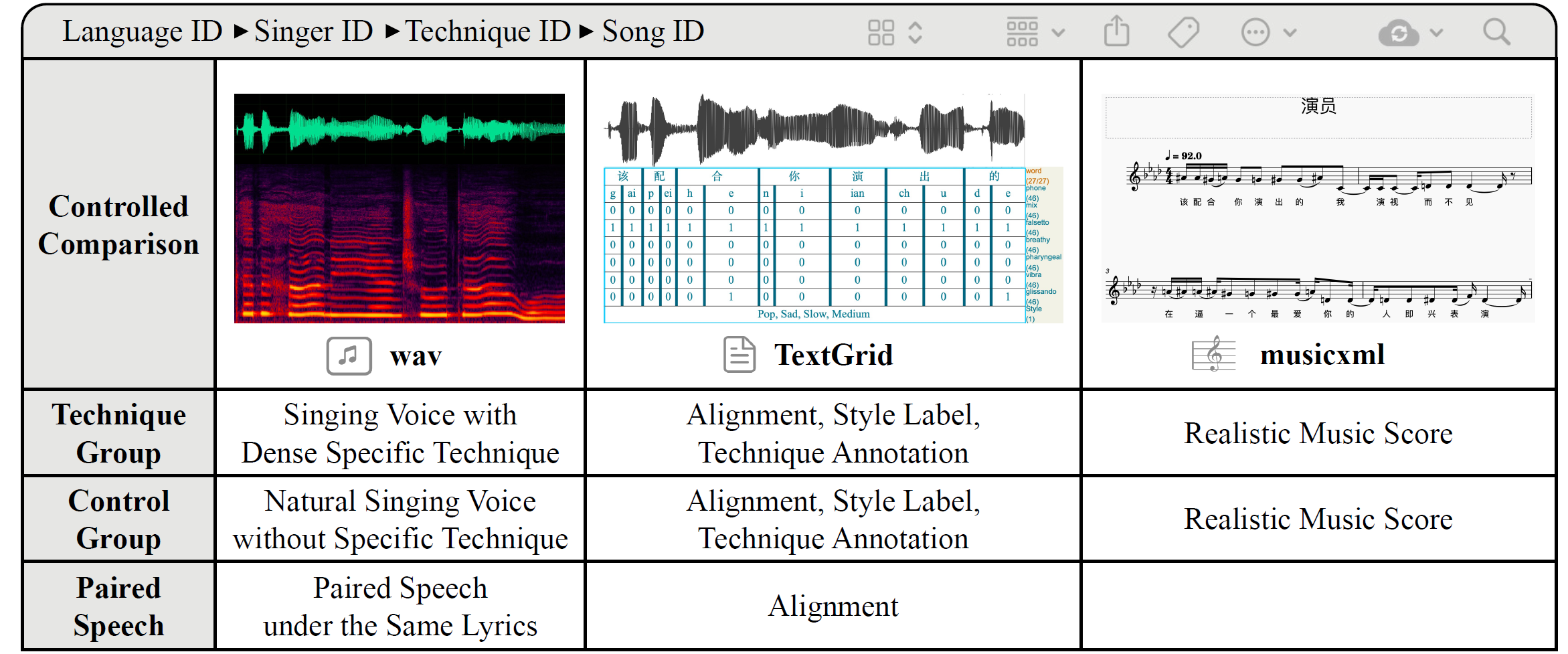
GTSinger: A Global Multi-Technique Singing Corpus with Realistic Music Scores for All Singing Tasks
Yu Zhang, Changhao Pan, Wenxinag Guo, et al.

- GTSinger is a large Global, multi-Technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks.
- Our work is promoted by multiple media and forums, such as
,
StyleSinger: Style Transfer for Out-of-Domain Singing Voice Synthesis
Yu Zhang, Rongjie Huang, Ruiqi Li, et al.

- StyleSinger is the first singing voice synthesis model for zero-shot style transfer of out-of-domain reference singing voice samples.
ACL 2025STARS: A Unified Framework for Singing Transcription, Alignment, and Refined Style Annotation, Wenxiang Guo*, Yu Zhang*, Changhao Pan*, et al. |AAAI 2025TechSinger: Technique Controllable Multilingual Singing Voice Synthesis via Flow Matching, Wenxiang Guo, Yu Zhang, Changhao Pan, et al. |ACL 2024Robust Singing Voice Transcription Serves Synthesis, Ruiqi Li, Yu Zhang, Yongqi Wang, et al. |IJCNLP-AACL 2025 OralSynthetic Singers: A Review of Deep-Learning-based Singing Voice Synthesis Approaches, Changhao Pan, Dongyu Yao, Yu Zhang, et al. |




💬 Speech
ASRU 2025Conan: A Chunkwise Online Network for Zero-Shot Adaptive Voice Conversion, Yu Zhang, Baotong Tian, Zhiyao Duan. |ACL 2026Rectifying the Emotional Flow: Aligning Priors and Dynamic Guidance for High-Arousal Text-to-Speech, Fangming Feng, Dongjie Fu, Zequn Xie, Yu Zhang et al.ReportMegaTTS 3: Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis, Ziyue Jiang, Yi Ren, Ruiqi Li, Shengpeng Ji, Zhenhui Ye, Chen Zhang, Bai Jionghao, Xiaoda Yang, Jialong Zuo, Yu Zhang, et al.ACL 2026Comprehensive Benchmarking of Long-Form Speech Generation in Diverse Scenarios, Changhao Pan, Rui Yang, Han Wang, Zhuan Zhou, Xuming He, Wenxiang Guo, Ziyue Jiang, Ruiqi Li, Yu Zhang et al.

💡 Others
IJCAI 2025Leveraging Pretrained Diffusion Models for Zero-Shot Part Assembly, Ruiyuan Zhang, Qi Wang, Jiaxiang Liu, Yu Zhang, et al.ReportALIVE: Animate Your World with Lifelike Audio-Video Generation, Ying Guo, Qijun Gan, Yifu Zhang, Jinlai Liu, Yifei Hu, Pan Xie, Dongjun Qian, Yu Zhang, et al.