
I am a PhD student at the College of Computer Science and Technology, Zhejiang University (浙江大学计算机学院).
I am now working on the Audio Research Team at Zhejiang University, under the supervision of Prof. Zhou Zhao (赵洲). My current research focuses on spatial audio generation based on multi-modal prompts.
I graduated from Chu Kochen Honors College, Zhejiang University (浙江大学竺可桢学院), with dual bachelor’s degrees in Computer Science and Automation.
I also worked as a visiting scholar at University of Massachusetts Amherst, collaborating with Prof. Przemyslaw Grabowicz.
My research interests primarily focus on Multi-Modal Generative AI, specifically in Singing and Music Synthesis, and Spatial Audio Generation. I have published first-author papers at top international AI conferences, including NeurIPS, AAAI, and EMNLP.
I am actively seeking postdoctoral positions and research collaborations. Please feel free to contact me via email at yuzhang34@zju.edu.cn.
🔥 News
- 2024.12: 🎉 1 paper is accepted by AAAI 2025!
- 2024.11: We released the code of TCSinger (Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control)!
- 2024.09: We released the full dataset of GTSinger (A Global Multi-Technique Singing Corpus for all singing tasks)!
- 2024.09: 🎉 1 paper is accepted by NeurIPS 2024 (Spotlight)!
- 2024.09: 🎉 1 paper is accepted by EMNLP 2024!
- 2024.06: We released the code of GTSinger (A Global Multi-Technique Singing Corpus for all singing tasks)!
- 2024.05: 🎉 1 paper is accepted by ACL 2024!
- 2024.05: We released the code of StyleSinger (Style Transfer for Out-of-Domain Singing Voice Synthesis)!
- 2023.12: 🎉 1 paper is accepted by AAAI 2024!
📝 Publications
🎤 Singing Voice Synthesis
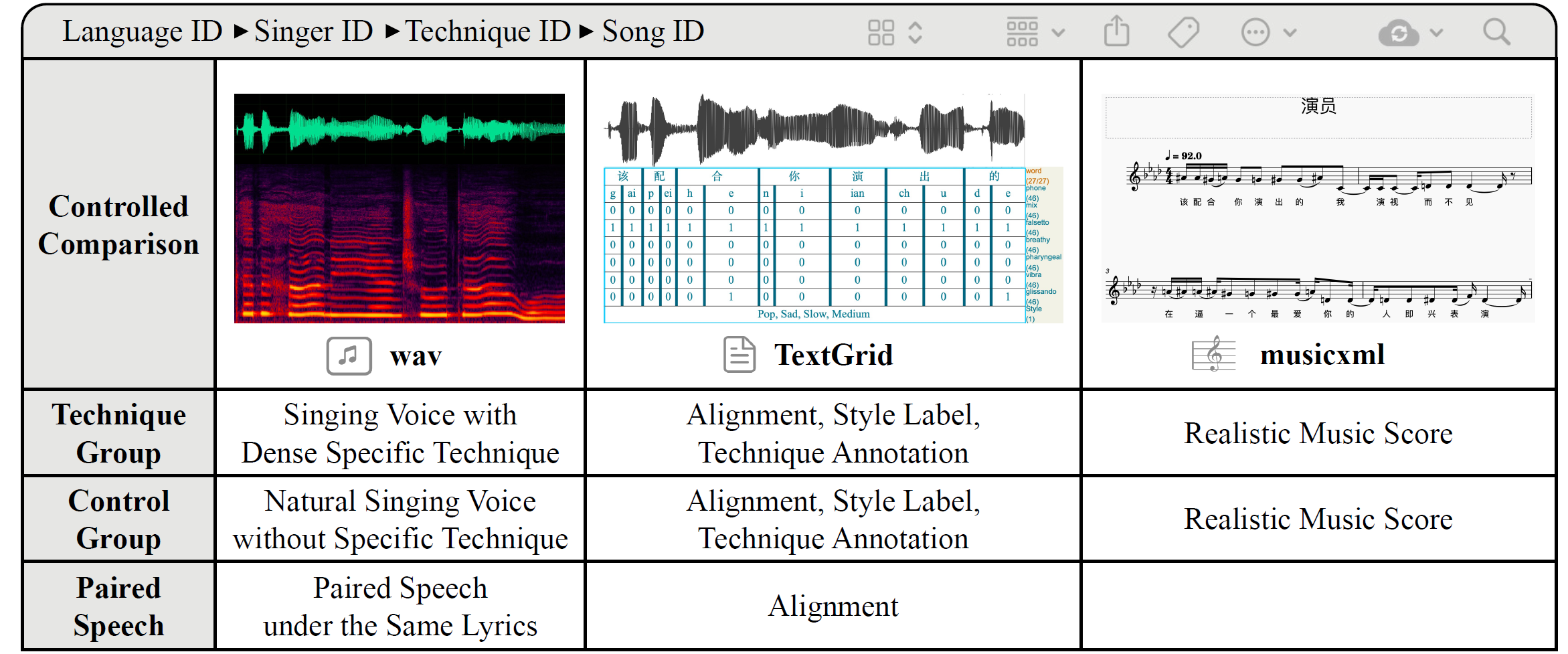
GTSinger: A Global Multi-Technique Singing Corpus with Realistic Music Scores for All Singing Tasks
Yu Zhang, Changhao Pan, Wenxinag Guo, et al.
Project | 
- GTSinger is a large Global, multi-Technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks.
- Our work is promoted by multiple media and forums, such as
,
, and
.
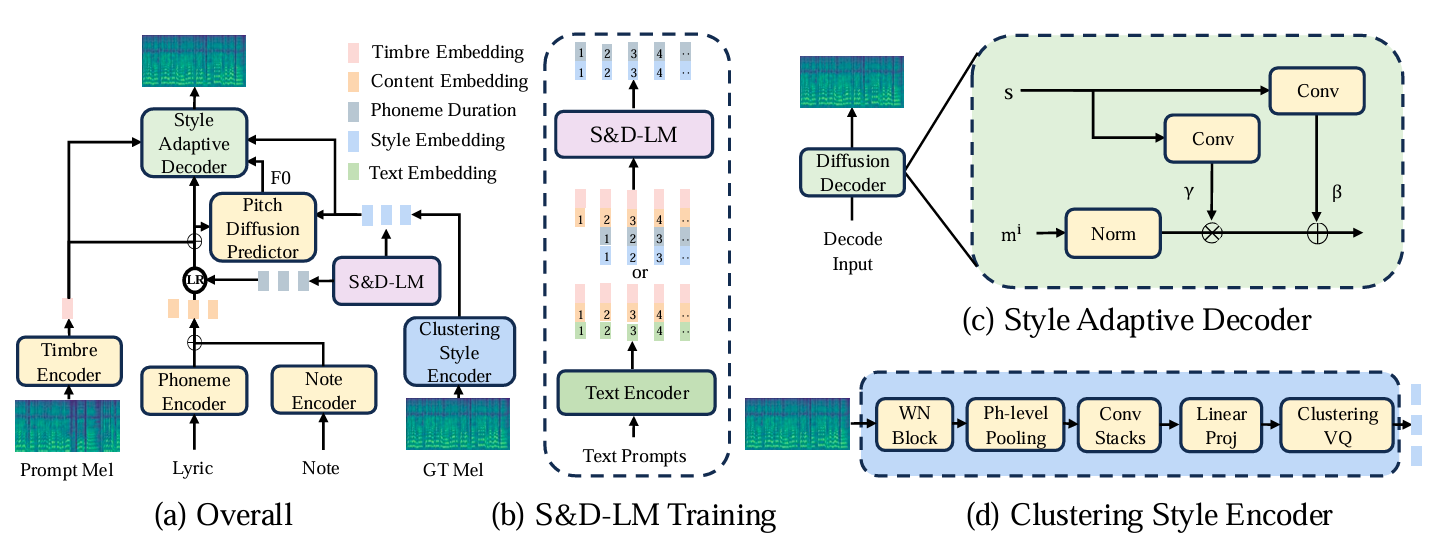
TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
Yu Zhang, Ziyue Jiang, Ruiqi Li, et al.
Project |

- TCSinger is the first zero-shot SVS model for style transfer across cross-lingual speech and singing styles, along with multi-level style control.
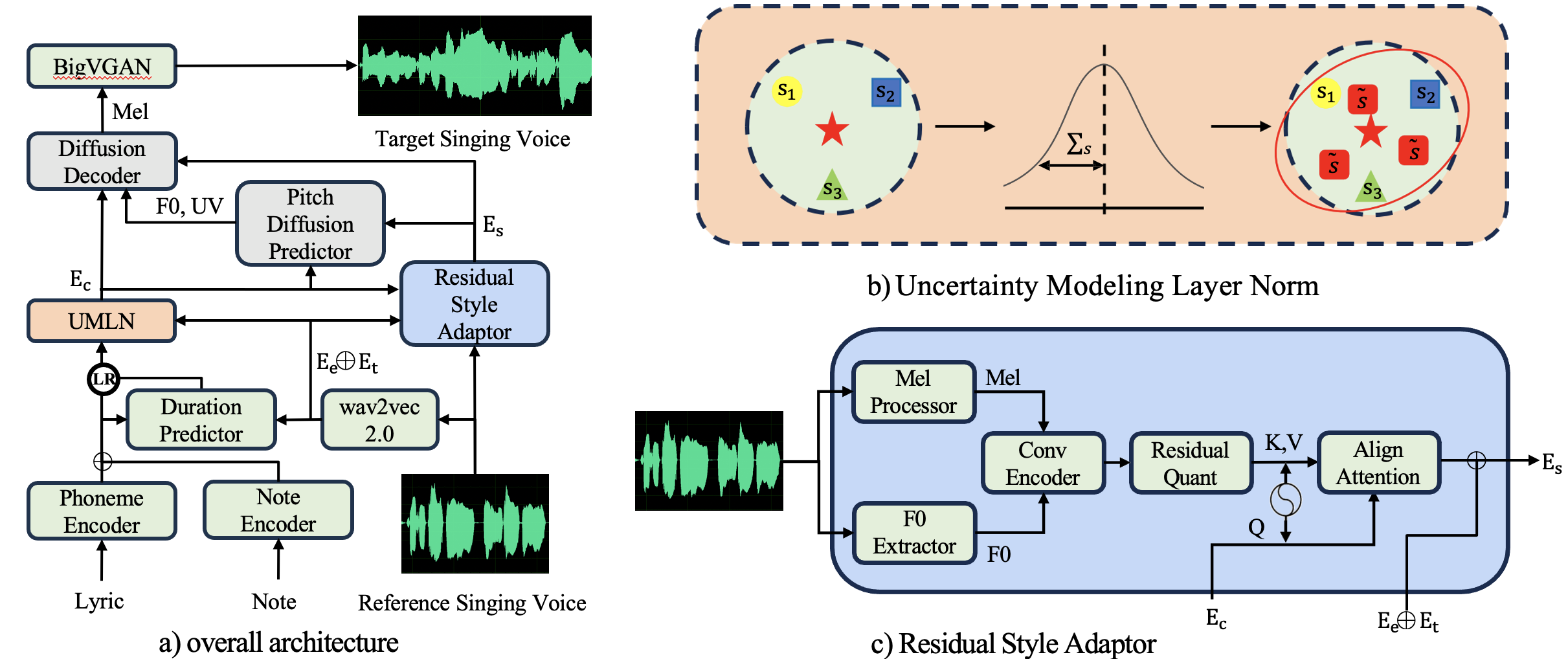
StyleSinger: Style Transfer for Out-of-Domain Singing Voice Synthesis
Yu Zhang, Rongjie Huang, Ruiqi Li, et al.
Project |

- StyleSinger is the first singing voice synthesis model for zero-shot style transfer of out-of-domain reference singing voice samples.
AAAI 2025TechSinger: Technique Controllable Multilingual Singing Voice Synthesis via Flow Matching, Wenxiang Guo, Yu Zhang, Changhao Pan, et al. | ProjectACL 2024Robust Singing Voice Transcription Serves Synthesis, Ruiqi Li, Yu Zhang, Yongqi Wang, et al. | Project |

🎙 Speech Synthesis
ArxivSparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis, Ziyue Jiang, Yi Ren, Ruiqi Li, Shengpeng Ji, Zhenhui Ye, Chen Zhang, Bai Jionghao, Xiaoda Yang, Jialong Zuo, Yu Zhang, et al. | Project
🎖 Honors and Awards
- 2024.09 Outstanding PhD Student Scholarship of Zhejiang University (Top 10%)
- 2020.06 Outstanding Graduate of Zhejiang University (Undergraduate) (Top 5%)
- 2019.09 First-Class Academic Scholarship of Zhejiang University (Undergraduate) (Top 5%)
📖 Educations
- 2020.09 - 2025.06 (Expected), PhD, Computer Science, College of Computer Science and Technology, Zhejiang University, Hangzhou, Zhejiang
- 2016.09 - 2020.06, Undergraduate, Computer Science & Automation, Chu Kochen Honors College, Zhejiang University, Hangzhou, Zhejiang
💻 Research and Internships
- 2020.06-2020.09 Alibaba-Zhejiang University Joint Institute of Frontier Technologies, working with Prof. Jianke Zhu
- 2019.07-2020.01 Visiting Scholar at University of Massachusetts Amherst, working with Prof. Przemyslaw Grabowicz.
- 2018.09-2019.06 Research Assistant at Institute of Cyber-Systems and Control in Zhejiang University, working with Prof. Chunlin Zhou.
📚 Academic Services
- Conference Reviewer/Assist to Review: ICLR 2025, EMNLP 2024, NeurIPS 2024, ACL 2024.